bRPC overview
What is RPC?
Most machines on internet communicate with each other via TCP/IP. However, TCP/IP only guarantees reliable data transmissions. We need to abstract more to build services:
- What is the format of data transmission? Different machines and networks may have different byte-orders, directly sending in-memory data is not suitable. Fields in the data are added, modified or removed gradually, how do newer services talk with older services?
- Can TCP connection be reused for multiple requests to reduce overhead? Can multiple requests be sent through one TCP connection simultaneously?
- How to talk with a cluster with many machines?
- What should I do when the connection is broken? What if the server does not respond?
- …
RPC addresses the above issues by abstracting network communications as “clients accessing functions on servers”: client sends a request to server, wait until server receives -> processes -> responds to the request, then do actions according to the result.
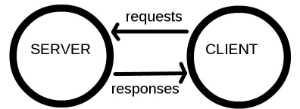
Let’s see how the issues are solved.
- RPC needs serialization which is done by protobuf pretty well. Users fill requests in format of protobuf::Message, do RPC, and fetch results from responses in protobuf::Message. protobuf has good forward and backward compatibility for users to change fields and build services incrementally. For http services, json is used for serialization extensively.
- Establishment and re-using of connections is transparent to users, but users can make choices like different connection types: short, pooled, single.
- Machines are discovered by a Naming Service, which can be implemented by DNS, ZooKeeper or etcd. Inside Baidu, we use BNS (Baidu Naming Service). brpc provides “list://” and “file://” as well. Users specify load balancing algorithms to choose one machine for each request from all machines, including: round-robin, randomized, consistent-hashing(murmurhash3 or md5) and locality-aware.
- RPC retries when the connection is broken. When server does not respond within the given time, client fails with a timeout error.
Where can I use RPC?
Almost all network communications.
RPC can’t do everything surely, otherwise we don’t need the layer of TCP/IP. But in most network communications, RPC meets requirements and isolates the underlying details.
Common doubts on RPC:
- My data is binary and large, using protobuf will be slow. First, this is possibly a wrong feeling and you will have to test it and prove it with profilers. Second, many protocols support carrying binary data along with protobuf requests and bypass the serialization.
- I’m sending streaming data which can’t be processed by RPC. Actually many protocols in RPC can handle streaming data, including ProgressiveReader in http, streams in h2, streaming rpc, and RTMP which is a specialized streaming protocol.
- I don’t need replies. With some inductions, we know that in your scenario requests can be dropped at any stage because the client is always unaware of the situation. Are you really sure this is acceptable? Even if you don’t need the reply, we recommend sending back small-sized replies, which are unlikely to be performance bottlenecks and will probably provide valuable clues when debugging complex bugs.
What is  ?
?
brpc is an Industrial-grade RPC framework using C++ Language, which is often used in high performance system such as Search, Storage, Machine learning, Advertisement, Recommendation etc.
You can use it to:
- Build a server that can talk in multiple protocols (on same port), or access all sorts of services
- restful http/https, h2/gRPC. using http/h2 in brpc is much more friendly than libcurl. Access protobuf-based protocols with HTTP/h2+json, probably from another language.
- redis and memcached, thread-safe, more friendly and performant than the official clients
- rtmp/flv/hls, for building streaming services.
- hadoop_rpc (may be opensourced)
- rdma support (will be opensourced)
- thrift support, thread-safe, more friendly and performant than the official clients.
- all sorts of protocols used in Baidu: baidu_std, streaming_rpc, hulu_pbrpc, sofa_pbrpc, nova_pbrpc, public_pbrpc, ubrpc, and nshead-based ones.
- Build HA distributed services using an industrial-grade implementation of RAFT consensus algorithm which is opensourced at braft
- Servers can handle requests synchronously or asynchronously.
- Clients can access servers synchronously, asynchronously, semi-synchronously, or use combo channels to simplify sharded or parallel accesses declaratively.
- Debug services via http, and run cpu, heap and contention profilers.
- Get better latency and throughput.
- Extend brpc with the protocols used in your organization quickly, or customize components, including naming services (dns, zk, etcd), load balancers (rr, random, consistent hashing)
Advantages of bRPC
More friendly API
Only 3 (major) user headers: Server, Channel, Controller, corresponding to server-side, client-side and parameter-set respectively. You don’t have to worry about “How to initialize XXXManager”, “How to layer all these components together”, “What’s the relationship between XXXController and XXXContext”. All you need to do is simple:
Build service? include brpc/server.h and follow the comments or examples.
Access service? include brpc/channel.h and follow the comments or examples.
Tweak parameters? Checkout brpc/controller.h. Note that the class is shared by server and channel. Methods are separated into 3 parts: client-side, server-side and both-side.
We tried to make simple things simple. Take naming service as an example. In older RPC implementations you may need to copy a pile of obscure code to make it work, however, in brpc accessing BNS is expressed as Init("bns://node-name", ...), DNS is Init("http://domain-name", ...) and local machine list is Init("file:///home/work/server.list", ...). Without any explanation, you know what it means.
Make services more reliable
brpc is extensively used in Baidu:
- map-reduce service & table storages
- high-performance computing & model training
- all sorts of indexing & ranking servers
- ….
It’s been proven.
brpc pays special attentions to development and maintenance efficency, you can view internal status of servers in web browser or with curl, analyze cpu hotspots, heap allocations and lock contentions of online services, measure stats by bvar which is viewable in /vars.
Better latency and throughput
Although almost all RPC implementations claim that they’re “high-performant”, the numbers are probably just numbers. Being really high-performant in different scenarios is difficult. To unify communication infra inside Baidu, brpc goes much deeper at performance than other implementations.
- Reading and parsing requests from different clients is fully parallelized and users don’t need to distinguish between “IO-threads” and “Processing-threads”. Other implementations probably have “IO-threads” and “Processing-threads” and hash file descriptors(fd) into IO-threads. When a IO-thread handles one of its fds, other fds in the thread can’t be handled. If a message is large, other fds are significantly delayed. Although different IO-threads run in parallel, you won’t have many IO-threads since they don’t have too much to do generally except reading/parsing from fds. If you have 10 IO-threads, one fd may affect 10% of all fds, which is unacceptable to industrial online services (requiring 99.99% availability). The problem will be worse when fds are distributed unevenly accross IO-threads (unfortunately common), or the service is multi-tenancy (common in cloud services). In brpc, reading from different fds is parallelized and even processing different messages from one fd is parallelized as well. Parsing a large message does not block other messages from the same fd, not to mention other fds. More details can be found here.
- Writing into one fd and multiple fds is highly concurrent. When multiple threads write into the same fd (common for multiplexed connections), the first thread directly writes in-place and other threads submit their write requests in wait-free manner. One fd can be written into 5,000,000 16-byte messages per second by a couple of highly-contended threads. More details can be found here.
- Minimal locks. High-QPS services can utilize all CPU power on the machine. For example, creating bthreads for processing requests, setting up timeout, finding RPC contexts according to response, recording performance counters are all highly concurrent. Users see very few contentions (via contention profiler) caused by RPC framework even if the service runs at 500,000+ QPS.
- Server adjusts thread number according to load. Traditional implementations set number of threads according to latency to avoid limiting the throughput. brpc creates a new bthread for each request and ends the bthread when the request is done, which automatically adjusts thread number according to load.
Check benchmark for a comparison between brpc and other implementations.